Recherche textuelle⚓︎
1. Introduction⚓︎
Une application de la recherche textuelle (de motif) est le séquençage des génomes.
Le séquençage du génome a conduit à une collaboration fructueuse entre généticiens et informaticiens et au développement de nouveaux algorithmes. En effet, on peut coder le génome avec les quatre lettres A, C, T et G qui sont les initiales de quatre bases nucléiques : adénine, cytosine, thymine et guanine. Du point de vue algorithmique, on considère donc des mots (très très longs) sur cet alphabet.
Voici un extrait d'un gène d'arabica :
AAGGTCCCTTATGATGCTGGCTTCTCTATTGATGATGATTACCAAGGAAGATCCCATTCCCCAGTATCCTGCGATGAACA
On souhaite dans cette partie trouver un algorithme efficace de recherche de motif dans un texte.
2. Recherche naïve⚓︎
Cadre du problème et notations⚓︎
On cherche donc la première occurrence d’un motif de longueur p dans un texte de longueur n.
On va faire "glisser" le motif sous le texte jusqu'à ce qu'il y ait une correspondance.
Pour savoir s'il a une correspondance, on doit comparer les caractères du motif à ceux qui leur font face dans le texte.
- S'il n'y a pas de correspondance pour un indice donné
i, on déplace la fenêtre. - Si le motif correspond, on a trouvé une occurrence à la position
i.
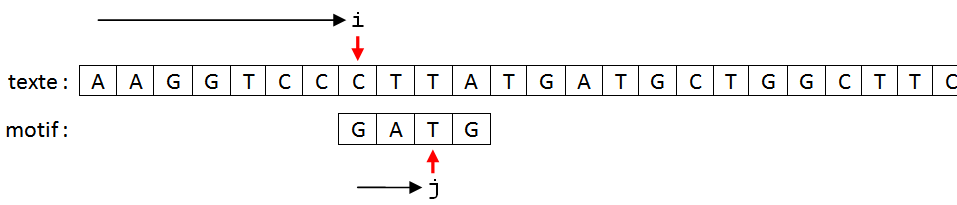
- Pour chaque caractère du motif, on va comparer
motif[j]àtexte[i+j]. - Les caractères du texte présents dans la fenêtre de comparaison sont numérotés de
iài + p - 1 - Précondition : pour que la recherche puisse se faire, on doit avoir l'inégalité
i < n - p
Recherche textuelle naïve, ou par force brute.⚓︎
L’algorithme naïf consiste simplement à comparer un à un, de gauche à droite, les caractères du texte apparaissant dans la fenêtre avec ceux du motif. En cas de non-correspondance on avance la fenêtre d’une unité vers la droite.
3. Principe de l'algorithme de Horspool, version simplifiée de l'algorithme de Boyer et Moore.⚓︎
Les faibles performances de la recherche naïve lorsque la taille du texte augmente (complexité moyenne O[T]), a poussé de nombreux
informaticiens à proposer des solutions pour améliorer la recherche.
L'algorithme de Boyer et Moore est un algorithme de recherche textuelle très efficace developpé en 1977. Robert Stephen Boyer et J Strother Moore travaillaient alors à l’université d’Austin au Texas en tant qu’informaticiens.
En 1980, Nigel Horspool a conçu une variante simplifiée de l'algorithme de Boyer-Moore.
C'est cette version qu'on va étudier dans ce paragraphe.
 |  |  |
| Robert Stephen Boyer | J Stroter Moore | Nigel Horspool |
3.1 Principe de l'algorithme d'Horspool⚓︎
Il s'appuie sur deux idées :
-
La première idée consiste à comparer le motif
Mavec la portion du texteTqui apparaît dans la fenêtre de droite à gauche, et non pas de gauche à droite.
Ainsi, on fait décroîtrejà partir dep − 1jusqu’à trouver une absence de correspondance, c’est-à-dire jusqu'à ce que le caractèrex = texte[i + j], soit différent du caractèrey = motif[j]. -
La deuxième idée consiste à opérer sur la fenêtre un décalage qui varie en fonction de la paire de caractères d'indice
(x, y)qui ont révélé la non-correspondance.
Visionner cette vidéo explicative
3.2 Calcul de la valeur du décalage du motif.⚓︎
Il est basé sur la position dans le motif de la dernière lettre du texte dans la fenêtre d'analyse : x = texte[i + (p-1)]
- Si la lettre
xn'apparait pas dans le motif alors on décale de la longueur du motif :decalage = p. - Si la lettre
xexiste dans le motif, la valeur du décalage est égale à la distance entre cette lettre et la fin du motif. Bien sûr on ne prend pas en compte la dernière lettre du motif, elle correspond à l'analyse qu'on vient de faire.
Exemple sur la séquence du génome

Il y a correspondance entre les G, mais pas entre la lettre précédente du texte (G) et la lettre précedente du motif (T). La lettre G du motif étant en première position du motif, la distance depuis la fin est de 3 : donc le décalage sera de 3.

Pas de correspondance sur les dernières lettres (C et G) et C n'est pas dans le motif, donc le décalage est de 4 (longueur du motif).

Pas de correspondance sur les dernières lettres (A et G) et A est à une distance de 2 depuis la fin : donc le décalage est de 2.

Il y a correspondance entre les lettres G, T et A, mais pas entre T et G. G est à une distance de 3 depuis la fin : donc le décalage est de 3.

Le motif correspond au texte : on a trouvé une occurence.
3.3 Le pré-traitement du motif.⚓︎
Grâce à la technique utilisée ci-dessus, on a gagné beaucoup puisqu'on a décalé le motif 5 fois au lieu de 12 pour la méthode naïve.
Mais on peut gagner encore en remarquant qu'on recherche la position de la lettre dans le motif pour chaque décalage.
L'idée est de calculer le décalage à effectuer pour chaque lettre du motif une fois pour toutes : le pré-traitement.
Exemple de tables de décalage
| Clé | Valeur |
|---|---|
| T | 1 |
| A | 2 |
| G | 3 |
| Autres caractères | 4 |
| Clé | Valeur |
|---|---|
| I | 1 |
| D | 2 |
| E | 3 |
| P | 4 |
| K | 6 |
| W | 8 |
| Autres caractères | 9 |
Dorénavant, en cas de non correspondance, on connait directement le décalage en fonction de la dernière lettre de la fenêtre de comparaison du texte (texte[i + (p-1)]).
En python, on pourra mettre la table sous forme d'un dictionnaire.
4. Algorithme de Boyer-Moore⚓︎
L'algorithme de Boyer-Moore contient déjà l'élaboration de la table vue dans l'algorithme de Horspoool. Mais afin d'améliorer encore l'efficacité de l'algorithme, il propose l'élaboration d'une seconde table.
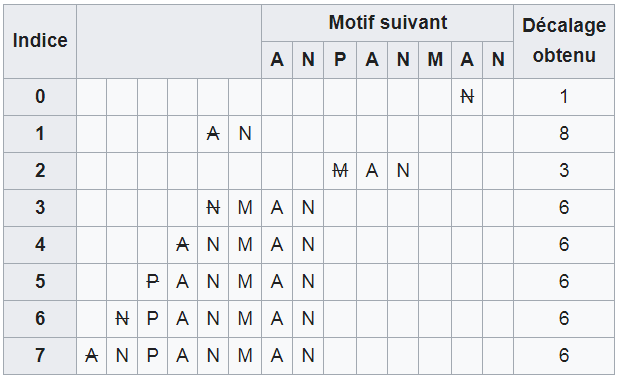
4.1 Seconde table de saut (indicée par la longueur de la clé comparée avec succès)1⚓︎
La seconde table est sensiblement plus compliquée à calculer : pour chaque valeur de j inférieure à la longueur p du motif,
il faut trouver le motif partiel composé des n derniers caractères du motif P, précédé d'un caractère qui ne correspond pas.
Puis, il faut trouver le plus petit nombre de caractères pour lesquels le motif partiel peut être décalé vers la gauche avant
que les deux motifs partiels ne correspondent.
Par exemple, pour le motif ANPANMAN de longueur de 8 caractères, la table de 8 lignes est remplie de cette manière (les motifs partiels déjà trouvés dans le texte sont montrés alignés dans des colonnes correspondant à l’éventuel motif partiel suivant possible, pour montrer comment s’obtient la valeur de décalage qui est la seule réellement calculée et stockée dans la seconde table de saut) :
Concernant les deux tables de sauts, on fait toujours les deux calculs, et on décale du maximum des deux décalages trouvés.